رشد تصاعدی دادهها در سالهای اخیر، مستلزم روششناسی قوی برای یکپارچهسازی و آمادهسازی دادهها است. فرایند استخراج، تبدیل، بارگذاری (ETL)، سنگ بنای انبار داده و هوش تجاری است که نقش مهمی در تبدیل دادههای خام به قالب مناسب برای تجزیهوتحلیل دارد.
در این مقاله به تعریف ETL و بیان سه مرحله اساسی در فرایند آن میپردازیم. تفاوت آن را با ELT بررسی کرده و پس از بیان مزایای آن، به کاربرد ETL در صنایع مختلف میپردازیم. با ما همراه باشید.
ETL چیست؟
ETL مخفف سه کلمه Extract، Transform و Load ، به معنای استخراج، تبدیل و بارگذاری، یک فرایند یکپارچهسازی داده است که داده ها را از چندین منبع مختلف ترکیب، پاکسازی و سازماندهی میکند و در قالب یک مجموعه داده منفرد و ثابت، برای ذخیرهسازی در یک انبار داده، دریاچه داده یا سایر سیستمهای هدف آماده میکند.
منابع دادهها میتوانند از نظر نوع، قالب، حجم و قابلیت اطمینان بسیار متنوع باشند، بنابراین دادهها باید پیش از ذخیرهسازی، پردازش شوند تا هنگام استفاده مفید باشند. بسته به اهداف و اجرای فنی، مخازن ذخیره داده هدف ممکن است پایگاه داده، انبار داده یا دریاچه داده باشند.
ETL پایه و اساس تحلیل داده ها و جریانهای کاری در یادگیری ماشین را فراهم میکند. فرایند ETL طبق قوانین تعریف شده در کسبوکار، دادهها را پاکسازی و سازماندهی میکند تا نیازهای خاص هوش تجاری، مانند گزارشگیری ماهانه را برطرف کند. همچنین میتواند در راستای بهبود فرایندهای back-end و تجربیات کاربر، به تجزیهوتحلیلهای پیشرفته نیز کمک کند. ETL اغلب در سازمانها برای موارد زیر استفاده میشود:
- استخراج داده ها از سیستمهای قدیمی
- پاکسازی داده ها برای بهبود کیفیت و ایجاد ثبات در آنها
- بارگذاری داده ها در پایگاه داده هدف
فرایند ETL چگونه است؟
سادهترین راه برای درک نحوه عملکرد ETL این است که بفهمیم در هر مرحله از این فرایند چه اتفاقی میافتد. فرایند ETL از سه مرحله متمایز به شرح زیر تشکیل شده است:
استخراج (Extract)
در حین استخراج، داده ها شناسایی شده و از منابع خود کپی میشوند؛ بنابراین ETL میتواند داده ها را به مخزن داده هدف منتقل کند. دادهها ممکن است از منابع ساختاریافته و بدون ساختار؛ از جمله اسناد، ایمیلها، اپلیکیشنها، نرم افزار ERP یا CRM، پایگاههای داده، وبسایت، تجهیزات، حسگرها، اشخاص ثالث و غیره به دست آیند.
تبدیل (Transform)
ازآنجاکه داده های استخراج شده در شکل اصلی خود و خام هستند، باید به فرمت مناسب تبدیل شوند تا برای ذخیره نهایی آماده شوند. در فرایند تبدیل، ETL دادهها را اعتبارسنجی، احراز یا حذف میکند، بهگونهای که دادههای حاصل برای پرسوجو قابلاعتماد باشند. این مرحله از فرایند ETL میتواند شامل مراحل زیر باشد:
- فیلترکردن، پاکسازی، تجمیع، کپیبرداری، اعتبارسنجی و احراز هویت داده ها،
- انجام محاسبات، ترجمه یا خلاصهسازی داده های خام؛ این مرحله میتواند شامل تغییر تیترهای سطر و ستون برای ایجاد سازگاری، تبدیل واحدهای پولی یا سایر واحدهای اندازهگیری، ویرایش رشتههای متنی و موارد دیگر باشد،
- انجام ممیزی برای اطمینان از کیفیت، انطباق داده ها و معیارهای محاسباتی،
- حذف، رمزگذاری یا محافظت از داده های تحت نظارت صنعت یا تنظیمکنندههای دولتی،
- قالببندی داده ها در جداول مجزا یا بههمپیوسته، برای مطابقت با طرحواره انبار داده هدف.
بارگذاری (Load)
در این مرحله، داده های تبدیل شده به مخزن داده هدف منتقل میشود. این مرحله میتواند شامل بارگیری اولیه همه داده های منبع یا بارگذاری تدریجی تغییرات ایجاد شده در داده های منبع باشد. درواقع میتوان داده ها را به شکل در لحظه یا برنامهریزیشده، بارگذاری کرد. برای اکثر سازمانهایی که از ETL استفاده میکنند، این فرایند به شکل خودکار، کاملاً تعریف شده، مستمر و دستهای است. به طور معمول، فرایند بارگذاری ETL در ساعاتی انجام میشود که ترافیک در سیستمهای منبع و انبار داده، در کمترین حد خود است.
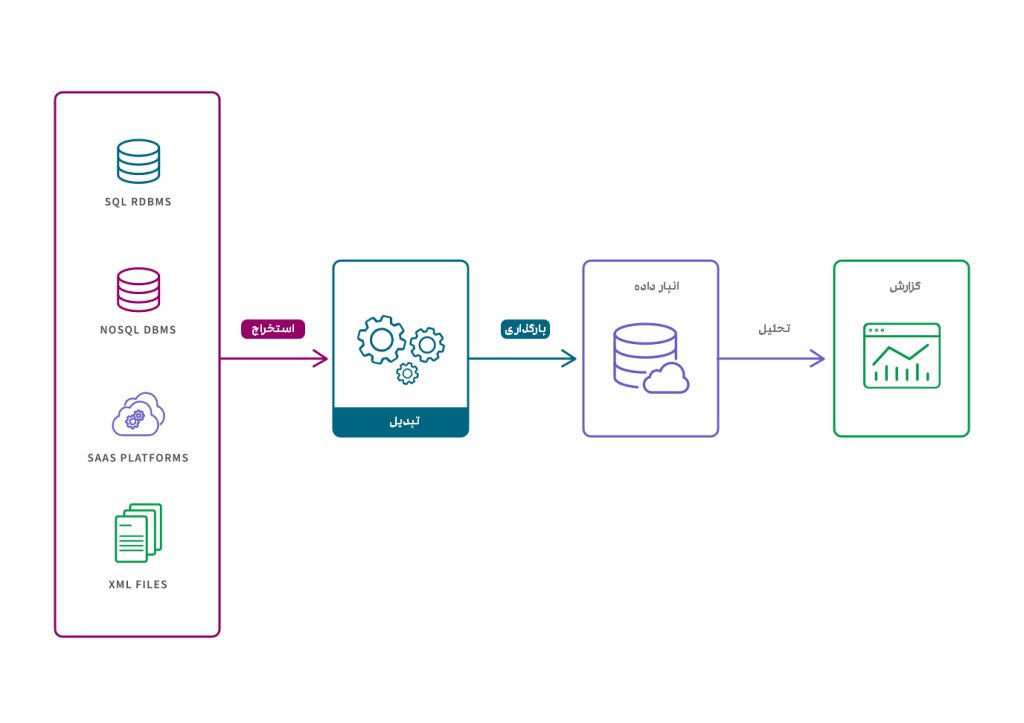
فرایند ETL
چرا ETL اهمیت دارد؟
امروزه سازمانها داده های ساختاریافته و بدون ساختار را از منابع مختلف جمعآوری میکنند، از جمله:
- داده های مشتری از سیستمهای پرداخت آنلاین و مدیریت ارتباط با مشتری (CRM)،
- داده های موجودی و عملیات از سیستمهای فروش،
- داده های حسگرها از دستگاههای اینترنت اشیا (IoT)،
- داده های بازاریابی از رسانههای اجتماعی و بازخورد مشتریان،
- داده های کارکنان از سیستمهای منابع انسانی داخلی.
با استفاده از فرایند استخراج، تبدیل و بارگذاری (ETL)، مجموعه دادههای خام را میتوان در قالب و ساختاری آماده کرد که برای مقاصد تحلیلی قابلمصرفتر باشد و در نتیجه، بینشهای معنادارتری به دست آید. برای مثال، خردهفروشان آنلاین میتوانند داده ها را از نقاط فروش جمعآوری کرده و آنها را برای پیشبینی تقاضا و مدیریت موجودی، تجزیهوتحلیل کنند. تیمهای بازاریابی نیز میتوانند برای مطالعه رفتار مصرفکننده، داده های CRM را با بازخوردهای مشتری در رسانههای اجتماعی ادغام کنند.
تفاوت ETL و ELT در چیست؟
استخراج، بارگذاری و تبدیل (ELT) توسعهای از فرایند ETL است که ترتیب عملیات را معکوس میکند. درواقع در این روش میتوان پیش از پردازش، داده ها را مستقیماً در سیستم هدف بارگذاری کرد؛ زیرا انبار داده هدف دارای قابلیت نقشهبرداری داده است. ELT با پذیرش زیرساختهای ابری که به پایگاههای اطلاعاتی هدف، قدرت پردازشی موردنیاز برای تغییرات را میدهد، محبوبیت بیشتری پیدا کرده است. مرحله تبدیل تا حد زیادی پیچیدهترین مرحله در فرایند ETL است؛ بنابراین، ETL و ELT در دو نکته اصلی متفاوت هستند:
- زمانی که تبدیل رخ میدهد
- محل تبدیل
بنابراین، واضحترین تفاوت میان ETL و ELT ، تفاوت در ترتیب عملیات آنها است. ELT دادهها را از منابع کپی میکند، اما بهجای بارگیری آنها برای تبدیل، دادههای خام را مستقیماً در مخازن داده هدف بارگذاری میکند تا در صورت نیاز، تبدیل شوند.
اگرچه هر دو فرایند از انواع مخازن داده ها مانند پایگاههای داده، انبارهای داده و دریاچههای داده استفاده میکنند، اما هر کدام دارای مزایا و معایب خود است. ELT برای مجموعه داده های بدون ساختار و دارای حجم بالا مفید است؛ زیرا بارگیری میتواند مستقیماً از منبع انجام شود. درواقع ELT میتواند برای مدیریت کلان داده ایدهآلتر باشد، زیرا نیازی به برنامهریزی اولیه برای استخراج و ذخیرهسازی داده ندارد.
فرایند ETL در ابتدا نیاز به تعریف بیشتری دارد. تجزیهوتحلیل باید از ابتدا در نظر گرفته شود تا انواع داده ها، ساختارها و روابط را تعریف کند. دانشمندان داده عمدتاً از ETL برای بارگذاری پایگاههای داده قدیمی در انبار داده استفاده میکنند و ELT امروزه به یک امر عادی تبدیل شده است.
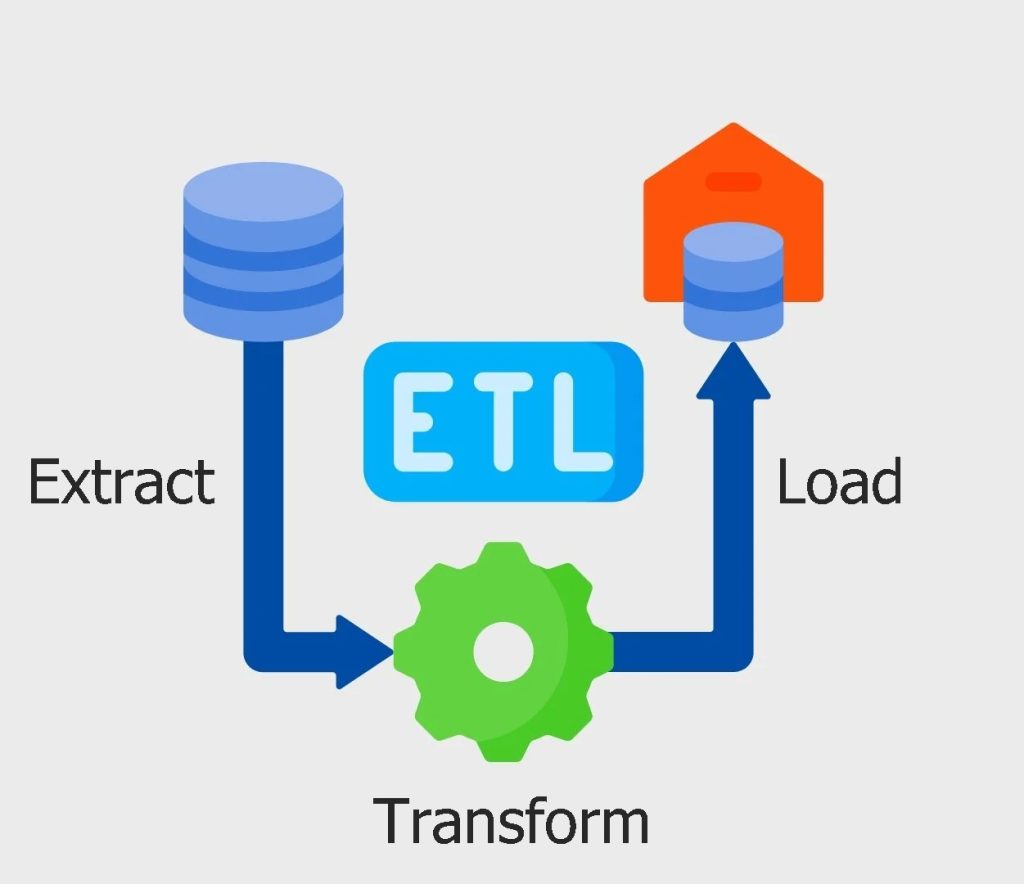
واضحترین تفاوت میان ETL و ELT ، تفاوت در ترتیب عملیات آنها است
مزایای ETL
راهحلهای ETL با پاکسازی داده ها قبل از بارگیری آنها در یک مخزن دیگر، کیفیت دیتا را بهبود میبخشد. ETL اغلب برای ایجاد مخازن دادههای هدف کوچکتر، که نیاز به بهروزرسانی کمتری دارند، توصیه میشود. درحالیکه سایر روشهای یکپارچهسازی دادهها از جمله ELT (استخراج، بارگذاری، تبدیل)، تغییر داده دریافت شده (CDC) و مجازیسازی دادهها، برای ادغام حجم فزایندهای از دادههایی که تغییر میکنند یا جریانهای داده در زمان واقعی استفاده میشوند.
از مهمترین مزایای ETL برای کسبوکارها میتوان به موارد زیر اشاره کرد:
- حفظ تاریخچه داده ها: ETL تاریخچه عمیقی از داده های یک سازمان ارائه میدهد. درواقع یک کسبوکار میتواند داده های قدیمی را با داده های پلتفرمها و برنامههای جدید ترکیب کند و بهاینترتیب، به دید بلندمدت نسبت به داده ها دست پیدا کند.
- ایجاد نمای تلفیقی از داده ها: ETL یک نمای تلفیقی از داده ها را برای تجزیهوتحلیل عمیق و گزارشگیری ارائه میدهد. مدیریت مجموعه داده های متعدد، مستلزم زمان و هماهنگی است و میتواند منجر به ناکارآمدی و تأخیر شود. ETL پایگاه داده ها و اشکال مختلف داده را در یک نمای واحد و یکپارچه ترکیب میکند. فرایند یکپارچهسازی داده ها کیفیت داده ها را بهبود میبخشد و در زمان لازم برای جابهجایی، طبقهبندی یا استانداردسازی داده ها صرفهجویی میکند. این امر تجزیهوتحلیل، تجسم داده و درک مجموعه داده های بزرگ را آسانتر میکند.
- تحلیل دقیق داده ها: ETL تجزیهوتحلیل دقیقتری را برای مطابقت با استانداردهای نظارتی داده ها ارائه میدهد. درواقع میتوان ابزارهای ETL را با ابزارهای کنترل کیفیت دادهها برای نمایهسازی، حسابرسی و پاکسازی دادهها ادغام کرده و اطمینان حاصل کرد که دادهها قابلاعتماد هستند.
- ایجاد اتوماسیون: ETL پردازش داده های قابلتکرار را برای تحلیل کارآمد آنها، خودکار میکند. ابزارهای ETL فرایند انتقال دادهها را خودکار میکنند و میتوان آنها را برای یکپارچهسازی تغییرات دادهها، بهصورت دورهای یا حتی در زمان اجرا، تنظیم کرد. در نتیجه، مهندسان داده میتوانند زمان بیشتری را صرف نوآوری و زمان کمتری برای مدیریت کارهای خستهکننده مانند جابهجایی و قالببندی داده ها، اختصاص دهند.
ابزارهای ETL
در گذشته، سازمانها خود نسبت به نوشتن کد ETL موردنیاز اقدام میکردند. در حال حاضر بسیاری از ابزارهای متنباز و خدمات مبتنی بر ابر برای انتخاب وجود دارد که مهمترین آنها عبارتاند از:
- ابزارهای پردازش دستهای (Batch Processing): به طور سنتی، پردازش دستهای در محل سازمان، از اولین فرایندهای ETL بود. در گذشته، پردازش مجموعهدادههای بزرگ بر قدرت محاسباتی سازمان تأثیر میگذاشت و بنابراین این فرایندها به شکل دستهای، در ساعات خلوتی سیستم انجام میشد. ابزارهای ETL امروزی هنوز هم میتوانند پردازش دستهای را انجام دهند، اما ازآنجاکه اغلب مبتنی بر ابر هستند، از نظر زمان و سرعت انجام پردازش محدودیت کمتری دارند.
- ابزارهای مبتنی بر ابر (Cloud-Native): ابزارهای ETL مبتنی بر ابر، میتوانند داده ها را از منابع، به شکل مستقیم در انبار داده ابری استخراج و بارگذاری کنند. این ابزارها در نهایت از قدرت و مقیاسپذیری بستر ابری، برای تبدیل داده ها استفاده میکنند.
- ابزارهای متنباز (Open Source): ابزارهای متنباز مانند آپاچی کافکا، جایگزین کمهزینهای برای ابزارهای تجاری ETL هستند. بااینحال، برخی از ابزارهای متنباز تنها از یک مرحله از فرایند ETL پشتیبانی میکنند؛ مانند استخراج داده ها. همچنین برخی از این ابزارها برای حل پیچیدگیهای داده یا تغییر داده دریافت شده (CDC) طراحی نشدهاند و پشتیبانی دشواری نیز دارند.
- ابزارهای در لحظه (Real-Time): کسبوکارهای امروزی نیازمند دسترسی بلادرنگ به داده ها هستند. این امر مستلزم آن است که سازمانها بتوانند داده ها را در لحظه، با یک مدل توزیع شده و قابلیتهای تشخیص جریان، پردازش کنند.
ETL و انبار داده
در گذشته، ابزارهای ETL در درجه اول برای تحویل داده ها به انبارهای داده سازمانی استفاده میشد که از نرم افزار BI پشتیبانی میکردند. چنین انبارهای دادهای طراحی شدهاند تا منبع قابلاعتمادی از حقیقت را در مورد همه آنچه در فعالیتهای یک سازمان اتفاق میافتد، نشان دهند. دادهها در این انبارها؛ با رعایت طرحوارهها، ابردادهها و قوانین سختگیرانهای که بر اعتبارسنجی دادهها حاکم است، ساختار دقیقی دارند.
ابزارهای ETL برای انبارهای داده سازمانی، باید الزامات یکپارچهسازی داده ها، مانند پردازش دستهای با حجم و عملکرد بالا را برآورده کنند. پس از بارگیری داده ها، استراتژیهای متعددی برای همگام نگهداشتن آنها میان منبع اصلی و منبع ذخیره داده هدف وجود دارد. میتوان مجموعه داده کامل را به شکل دورهای بارگیری مجدد کرد، بهروزرسانیهای دورهای آخرین دادهها را برنامهریزی کرده یا متعهد شد که هماهنگی کامل میان منبع و انبار داده هدف حفظ میشود.
ETL و دیتا مارت
دیتا مارت ها، انبارهای داده هدف کوچکتر و متمرکزتری نسبت به انبارهای داده سازمانی هستند. برای مثال، آنها میتوانند روی اطلاعات مربوط به یک بخش یا یک خط محصول واحد تمرکز کنند. به همین دلیل، کاربران ابزارهای ETL برای این دادهها، اغلب متخصصان خط، تحلیلگران داده و/یا دانشمندان داده هستند.
ابزارهای ETL برای دادهها باید توسط پرسنل کسبوکار و مدیران داده قابلاستفاده باشد تا برنامهنویسان و کارکنان فناوری اطلاعات. بنابراین، این ابزارها باید گردش کار بصری داشته باشند تا راهاندازی جریان داده ها برای فرایند ETL را آسان کنند.

دیتا مارت ها، انبارهای داده هدف کوچکتر و متمرکزتری نسبت به انبارهای داده سازمانی هستند
ETL یا ELT و دریاچه داده
دریاچههای داده از الگوی متفاوتی نسبت به انبارهای داده و مارت های داده پیروی میکنند. دریاچههای داده عموماً دادههای خود را در اشیا یا سیستمهای فایل توزیعشده Hadoop (HDFS) ذخیره میکنند و بنابراین میتوانند دادههای با ساختار کمتر را، بدون طرحواره ذخیره کنند. همچنین دریاچههای داده از ابزارهای متعددی برای پرسوجو در داده های بدون ساختار پشتیبانی میکنند.
یک الگوی دیگر در دریاچه داده، فرایند استخراج، بارگذاری و تبدیل (ELT) است که در آن، داده ها ابتدا «همانطور که هستند» ذخیره و پس از جمعآوری در دریاچه داده، تبدیل، تجزیهوتحلیل و پردازش میشوند. این الگو چند مزیت را ارائه میدهد:
- همه داده ها ثبت میشود و هیچ دادهای به دلیل فیلترشدن از بین نمیرود،
- داده ها را میتوان بسیار سریع ذخیره کرد که این موضوع برای جریان داده های اینترنت اشیا (IoT)، داده های وبسایت و غیره مفید است،
- امکان کشف روندهایی را فراهم میکند که در زمان ذخیره مورد انتظار نبودند،
- امکان بهکارگیری تکنیکهای هوش مصنوعی (AI) را فراهم میکند که در تشخیص الگو در مجموعه کلاندادهها و داده های بدون ساختار برتری دارند.
کاربرد ETL در صنایع
ETL به دلیل توانایی در ذخیره سریع و مطمئن داده ها در دریاچههای داده؛ در راستای کاربردهایی در علم داده، تحلیل دیتا و ایجاد مدلهای باکیفیت بالا، برای بسیاری از صنایع فرایندی اساسی است. راهحلهای ETL همچنین میتوانند دادههای تراکنشهای یک کسبوکار را در مقیاس بالا، بارگذاری و تبدیل کنند تا یک نمای سازمانیافته از کلاندادهها ایجاد و بهاینترتیب، روندهای صنعت را تجسم و پیشبینی کنند. از صنایعی که برای ایجاد بینش عملی، تصمیمگیری سریع و کارایی بیشتر به ETL متکی هستند، میتوان به موارد زیر اشاره کرد.
- حوزه مالی: مؤسسات ارائهدهنده خدمات مالی، مقادیر زیادی از داده های ساختاریافته و بدون ساختار را جمعآوری میکنند تا در مورد رفتار مصرفکننده، بینشهایی را جمعآوری کنند. این بینشها میتوانند ریسکها را تجزیهوتحلیل کنند، خدمات مالی بانکها را بهینه کرده و عملکرد پلتفرمهای آنلاین را بهبود بخشند.
- نفت و گاز: کسبوکارهای فعال در صنعت نفت و گاز از راهحلهای ETL برای پیشبینی در مورد استفاده، ذخیرهسازی و روند توسعه در مناطق جغرافیایی خاص استفاده میکنند. فرایند ETL حداکثر اطلاعات ممکن را از تمام حسگرهای یک سایت استخراج و جمعآوری کرده و به پردازش بهتر اطلاعات کمک میکند.
- خودروسازی: راهحلهای ETL میتوانند نمایندگیها و تولیدکنندگان خودرو را قادر به درک الگوهای فروش، بهبود کمپینهای بازاریابی، تأمین موجودی و پیگیری سرنخهای مشتری کنند.
- مخابرات: با حجم و تنوع بیسابقه دادههایی که امروزه تولید میشود، ارائهدهندگان خدمات ارتباطات از راه دور، برای مدیریت و درک بهتر دادهها به راهحلهای ETL تکیه میکنند. هنگامی که این داده ها پردازش و تحلیل شدند، سازمانها میتوانند از آنها برای بهبود تبلیغات، رسانههای اجتماعی، سئو، رضایت مشتری، سودآوری و موارد دیگر استفاده کنند.
- مراقبتهای بهداشتی: با افزایش نیاز جامعه به کاهش هزینههای درمان و همچنین بهبود مراقبتهای بهداشتی، صنعت پزشکی و درمان از راهحلهای ETL برای مدیریت سوابق بیمار، جمعآوری اطلاعات بیمه و برآوردهکردن الزامات قانونی در حال تغییر، استفاده میکند.
- علوم زیستی: آزمایشگاههای بالینی برای پردازش انواع دادههای تولید شده توسط مؤسسات تحقیقاتی، به راهحلهای ETL و هوش مصنوعی (AI) متکی هستند. برای مثال، همکاری در ساخت واکسن نیاز به حجم عظیمی از داده ها برای جمعآوری، پردازش و تجزیهوتحلیل دارد.
- بخش عمومی: با ظهور سریع قابلیتهای اینترنت اشیا (IoT)، شهرهای هوشمند از فرایند ETL و قدرت هوش مصنوعی برای بهینهسازی ترافیک، نظارت بر کیفیت آب، بهبود پارکینگ و موارد دیگر استفاده میکنند.
همانطور که در این مقاله به آن اشاره شد، ETL سنگ بنای یکپارچه سازی داده ها در سازمان است که داده های خام را به یک قالب مناسب برای تحلیل دیتا تبدیل می کند. همانطور که چشماندازهای دادهها تکامل پیدا میکنند، فرایند ETL نیز به طور مداوم با آنها تطبیق پیدا کند تا این اطمینان حاصل شود که سازمانها به طور موثر از دادههای خود برای تصمیم گیری آگاهانه استفاده میکنند.
منابع
- ibm.com
- oracle.com
- aws.amazon.com
- qlik.com