
در عصر کلان داده، سازمانها به طور فزایندهای با چالش جمعآوری، ذخیره و تجزیهوتحلیل حجم وسیعی از داده ها از منابع متنوع مواجه میشوند. این داده ها میتوانند ساختاریافته، نیمهساختاریافته یا بدون ساختار باشند و همه چیز را، از ورودیهای پایگاه داده رابطهای تا پستهای رسانههای اجتماعی، داده های حسگرها و فایلهای ویدئویی، در برمیگیرند. برای مقابله با این چالش، مفهوم دریاچه داده به عنوان یک پارادایم مرکزی برای مدیریت داده ظاهر شده است.
هرچه افراد و کسبوکارها بیشتر به دنبال کشف دانش موجود در داده های گستردهتری باشند، اهمیت وجود دریاچههای داده بیشتر میشود؛ زیرا گردآوری داده ها را در یک مکان ممکن میکند. این مقاله مقدمهای جامع در مورد دریاچههای داده ارائه میدهد.
تعریف دریاچههای داده و بررسی ویژگیهای کلیدی آنها، ملاحظات مربوط به طراحی و اجرای معماری دریاچه داده، مزایای Data lake و نقش آنها را در تسهیل وظایف مختلف تجزیهوتحلیل داده؛ مانند هوش تجاری، تجزیهوتحلیل پیشرفته و یادگیری ماشین از مهمترین مواردی است که در این مقاله به آنها پرداخته میشود.
دریاچه داده چیست؟
دریاچه داده یک مخزن ذخیرهسازی است که حجم زیادی از داده های خام را در فرمت اصلی خود نگهداری میکند تا زمانی که برای استفاده در برنامههای تحلیلی، موردنیاز باشند. درواقع دریاچه داده یک مخزن متمرکز است که امکان ذخیرهسازی تمام داده های ساختاریافته و بدون ساختار را، در هر مقیاسی فراهم میکند. بهاینترتیب، میتوان دادهها را همانطور که هستند، بدون نیاز به ساختاربندی، ذخیره و انواع مختلفی از تجزیه و تحلیلها را اجرا کرد؛ از داشبوردها و تجسم داده تا پردازش کلان داده، تجزیهوتحلیل در لحظه و یادگیری ماشینی برای اخذ تصمیمهای بهتر.
درحالیکه یک انبار داده، دیتا را در جداول سلسلهمراتبی ذخیره میکند، دریاچه داده از یک معماری مسطح برای ذخیره داده ها، در درجه اول در فایلها یا اشیا استفاده میکند؛ این قابلیت به کاربران انعطافپذیری بیشتری در مدیریت داده، ذخیرهسازی و استفاده از آنها میدهد.
دریاچههای داده اغلب با سیستمهای Hadoop مرتبط هستند. در استقرارهای مبتنی بر چارچوب پردازش توزیع شده (Distributed Processing Framework)، داده ها در سیستم فایل توزیع شده Hadoop (HDFS) بارگذاری میشوند و در گرههای مختلف، در یک خوشه Hadoop قرار میگیرند. بااینحال، امروزه به طور فزایندهای، دریاچههای داده بهجای Hadoop ، روی سرویسهای ذخیرهسازی اشیای ابری ساخته میشوند. برخی از پایگاههای داده NoSQL نیز به عنوان پلتفرمهای دریاچه داده مورد استفاده قرار میگیرند.
چرا کسبوکارها از دریاچه داده استفاده میکنند؟
دریاچههای داده معمولاً مجموعهای از کلان داده ها را ذخیره میکنند که میتوانند شامل ترکیبی از دادههای ساختاریافته، بدون ساختار و نیمهساختاریافته باشند. چنین فضایی برای استفاده در پایگاه داده های رابطهای که انبارهای داده روی آنها ساخته شدهاند، مناسب نیستند. درواقع سیستمهای رابطهای به یک طرحواره سفتوسخت برای داده ها نیاز دارند که این موضوع آنها را به ذخیره داده های ساختاریافته محدود میکند. دریاچههای داده از طرحوارههای مختلفی پشتیبانی میکنند که آنها را قادر میسازد تا انواع مختلف داده ها را در قالبهای جداگانه مدیریت کنند.
در نتیجه، دریاچههای داده یک جزء کلیدی در معماری داده بسیاری از سازمانها هستند. کسبوکارها عمدتاً از data lakeها بهعنوان پلتفرمی برای تحلیل دادههای بزرگ و سایر کاربردهای علم داده که به حجم زیادی از دادهها نیاز دارند و شامل تکنیکهای تحلیلی پیشرفته؛ مانند داده کاوی، مدلسازی پیشبینیکننده و یادگیری ماشین هستند، استفاده میکنند.

دریاچه داده یک جزء کلیدی در معماری داده بسیاری از سازمانها است
آمارها نشان میدهند سازمانهایی که با موفقیت از داده های خود ارزش تجاری ایجاد میکنند، از رقبای خود بهتر عمل میکنند. یک نظرسنجی نشان میدهد کسبوکارهایی که در معماری داده خود دریاچه داده را پیادهسازی کردهاند، در رشد درآمد ارگانیک 9 درصد از شرکتهای مشابه پیشی گرفتهاند. این رهبران با استفاده از data lake، قادر به انجام انواع جدیدی از تجزیه و تحلیلها مانند یادگیری ماشینی، از منابع جدید مانند گزارشها، جریان کلیکها، رسانههای اجتماعی و دستگاههای متصل به اینترنت بودند. این موضوع به سازمانها کمک میکند تا با جذب و حفظ مشتریان، افزایش بهرهوری، نگهداری فعالانه دستگاهها و تصمیمگیری آگاهانه، فرصتهای رشد کسبوکار را سریعتر شناسایی کرده و بر اساس آنها عمل کنند.
همچنین دریاچه داده منبعی متمرکز را برای دانشمندان داده و تحلیلگران فراهم میکند تا داده های موردنیاز خود را پیدا، آماده و تجزیهوتحلیل کنند. بدون data lake، انجام این فرایند پیچیدهتر بوده و استفاده از داده ها برای به اتخاذ تصمیمات و استراتژیهای تجاری آگاهانهتر، برای کسبوکارها دشوار میشود.
معماری دریاچه داده
در طراحی دریاچههای داده میتوان از فناوریهای بسیاری استفاده کرد و سازمانها میتوانند آنها را به روشهای مختلف، با یکدیگر ترکیب کنند. این موضوع بدان معناست که معماری دریاچه داده از سازمانی به سازمان دیگر متفاوت است. بهعنوانمثال، یک شرکت ممکن است Hadoop را با موتور پردازش Spark و HBase و یک پایگاه داده NoSQL که در بالای HDFS اجرا میشود، مستقر کند. دیگری ممکن است Spark را در برابر داده های ذخیره شده در سرویس ذخیرهسازی ساده آمازون (S3) اجرا کند.
همچنین، همه دریاچههای داده فقط داده های خام را ذخیره نمیکنند. درواقع برای مجموعههای دادههایی که ممکن است فیلتر شده و برای تجزیهوتحلیل پردازش شده باشند، معماری دریاچه داده میتواند این امکان را فراهم کرده و ظرفیت ذخیرهسازی کافی برای داده های آماده را داشته باشد. بسیاری از دریاچههای داده همچنین شامل سندباکسهای تحلیلی (Analytics Sandboxes) و فضاهای ذخیرهسازی اختصاصی هستند که دانشمندان داده میتوانند از آنها برای کار با داده ها استفاده کنند.
بااینحال، سه اصل اساسی معماری، دریاچههای داده را از مخازن داده های معمولی متمایز میکند:
- هر دادهای که از سیستمهای منبع جمعآوری میشود را میتوان در صورت تمایل، در یک دریاچه داده بارگیری و نگهداری کرد،
- داده ها را میتوان همانطور که از سیستم منبع دریافت شده است، یا با تغییرات اندک ذخیره کرد،
- دادههای خام را میتوان در صورت نیاز، بر اساس الزامات تحلیلی خاص، در یک طرحواره قرار داد؛ رویکردی که به عنوان schema-on-read شناخته میشود.
هر فناوری که در استقرار دریاچه داده استفاده شود، باید عناصر دیگری را نیز در خود بگنجاند تا اطمینان حاصل شود که دریاچه داده عملکرد مناسب را دارد و داده های موجود در آن هدر نمیروند. این عناصر شامل موارد زیر است:
- یک ساختار پوشه مشترک با قراردادهای نامگذاری،
- یک کاتالوگ داده قابل جستجو برای کمک به کاربران در یافتن و درک داده ها،
- طبقهبندی دادهها برای شناسایی دادههای حساس؛ با اطلاعاتی مانند نوع داده، محتوا، سناریوهای استفاده و گروههایی از کاربران احتمالی،
- ابزارهای پروفایل داده برای ارائه بینش درمورد طبقهبندی داده ها و شناسایی مسائل مربوط به کیفیت دیتا،
- یک فرایند استاندارد دسترسی به داده برای کمک به کنترل و پیگیری افرادی که به داده ها دسترسی دارند،
- حفاظت از داده ها؛ مانند پوشاندن داده ها، رمزگذاری آنها و نظارت بر استفاده خودکار.
یکی از موارد ضروری درگیر در معماری دریاچه داده، آگاهی از داده در میان کاربران آن است؛ بهخصوص اگر شامل کاربرانی باشد که به عنوان دانشمند داده عمل میکنند. کاربران علاوه بر آموزش نحوه پیمایش در دریاچه داده، باید شیوه مدیریت صحیح داده ها، تکنیکهای حفظ کیفیت داده و همچنین حاکمیت داده و سیاستهای استفاده از داده در سازمان را بدانند.
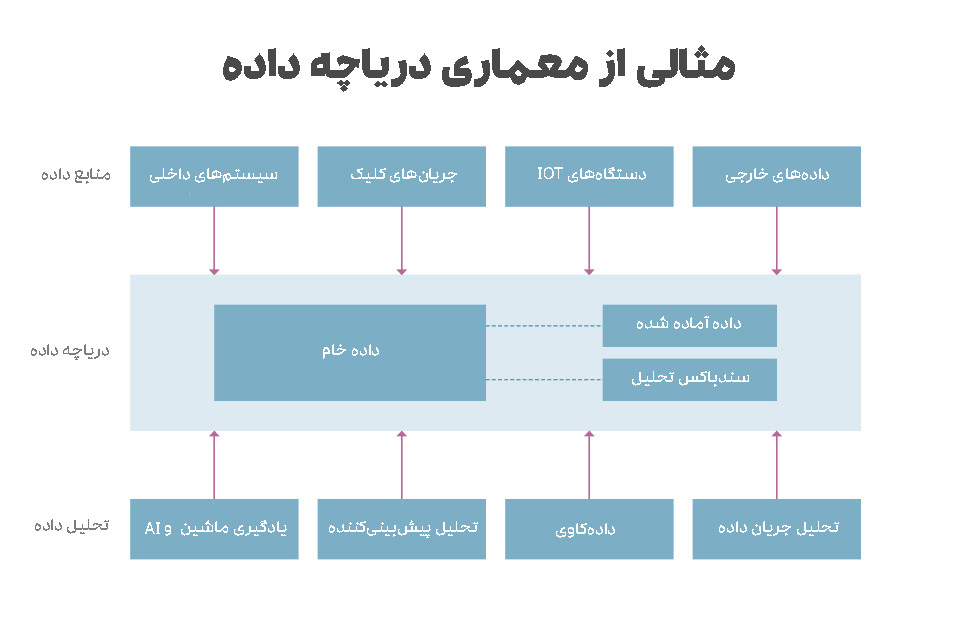
مثال معماری دریاچه داده
تفاوت انبار داده و دریاچه داده
بسته به الزامات، یک سازمان معمولی به انبار داده و دریاچه داده نیاز دارد؛ زیرا هرکدام نیازهای مختلفی را برآورده میکنند.
انبار داده، یک پایگاه داده است که برای تحلیل داده های رابطهای که از سیستمهای تراکنش و برنامههای تجاری به دست میآید، بهینه شده است. در datawarehouse، ساختار داده و طرحواره از قبل برای بهینهسازی پرسوجوهای سریع SQL تعریف شدهاند؛ جایی که نتایج معمولاً برای گزارشگیری و تجزیهوتحلیل عملیاتی استفاده میشوند. در انبار داده، داده ها تمیز شده، بارگذاری و تبدیل میشوند تا بتوانند به عنوان یک «منبع واحد حقیقت» که کاربران میتوانند به آن اعتماد کنند، عمل کند.
دریاچه داده با انبار داده متفاوت است، زیرا دادههای رابطهای را از برنامههای تجاری و دادههای خام را از برنامههای تلفن همراه، دستگاههای IoT و رسانههای اجتماعی ذخیره میکند. درواقع هنگام جمعآوری دادهها، ساختار داده یا طرحواره تعریف نمیشود. این بدان معنی است که میتوان تمام داده ها را بدون طراحی دقیق یا نیاز به دانستن اینکه در آینده برای چه سؤالاتی مورد استفاده قرار میگیرند، ذخیره کرد. بهاینترتیب میتوان انواع مختلف تجزیهوتحلیل داده ها مانند پرسوجوهای SQL، تحلیل بیگ دیتا، جستجوی متن، تحلیل بلادرنگ و یادگیری ماشینی را برای کشف بینش مورد استفاده قرار داد.
بنابراین، بزرگترین تمایز میان دریاچه داده و انبار داده در پشتیبانی آنها از انواع داده و رویکردشان به طرحوارهها است. در یک انبار داده که عمدتاً داده های ساختاریافته را ذخیره میکند، طرحواره برای مجموعه داده ها از پیش تعیین شده است و برنامهای برای پردازش، تبدیل و استفاده از داده ها (ETL) هنگام بارگیری در انبار وجود دارد. این موضوع لزوماً در یک دریاچه داده صادق نیست! درواقع data lake میتواند انواع مختلفی از داده ها را در خود جای دهد و نیازی به داشتن یک طرحواره تعریف شده یا برنامه خاصی برای نحوه استفاده از داده ها ندارد.
برای نشاندادن تفاوت بین این دو موضوع، میتوان یک انبار واقعی را با یک دریاچه مقایسه کرد. دریاچه به شکل مایع، متحرک و بدون شکل مشخص است و از رودخانهها، نهرها و دیگر منابع آب تصفیه نشده تغذیه میشود. برعکس، انبار سازهای است با قفسهها، راهروها و مکانهای تعیینشده برای نگهداری اقلامی که در آن وجود دارد و به طور هدفمند، برای مصارف خاص تهیه میشود.

مقایسه دریاچه داده و انبا
تفاوت مفهومی میان دریاچه داده و انبار داده را میتوان در ابعاد مختلف مورد بررسی قرار داد، از جمله:
- پلتفرمهای فناوری: معماری انبار داده معمولاً شامل یک پایگاه داده رابطهای است که روی یک سرور معمولی اجرا میشود، درحالیکه دریاچه داده معمولاً در یک خوشه Hadoop یا سایر محیطهای کلان داده مستقر میشود.
- منابع داده: دادههای ذخیرهشده در انبار داده عمدتاً از برنامههای پردازش تراکنشهای داخلی برای پشتیبانی از هوش تجاری (BI) و پرسشهای ایجاد شده جهت گزارشدهی اولیه استخراج میشوند. دریاچههای داده معمولاً ترکیبی از دادههای کسبوکار و سایر منابع داخلی و خارجی مانند وبسایتها، دستگاههای IoT، رسانههای اجتماعی و برنامههای تلفن همراه را ذخیره میکنند.
- کاربران: انبارهای داده برای تجزیهوتحلیل داده های مدیریت شده از سیستمهای عملیاتی، از طریق پرسوجوهای ایجاد شده توسط تیم BI یا تحلیلگران تجاری و سایر کاربران سلفسرویس BI مفید هستند. ازآنجاکه دادههای موجود در دریاچه دادهها اغلب نامشخص هستند و میتوانند از منابع مختلفی سرچشمه بگیرند، معمولاً برای کاربر متوسط BI مناسب نیست. در عوض، دریاچههای داده برای استفاده توسط دانشمندان داده که مهارت مرتبسازی دادهها و استخراج معنا از آن را دارند، مناسبتر هستند.
- کیفیت داده: دادههای موجود در انبار داده عموماً بهعنوان منبعی قابلاعتماد در نظر گرفته میشوند؛ زیرا برای یافتن و رفع خطاها؛ ادغام، پیشپردازش و پاکسازی شدهاند. دادههای موجود در دریاچه دادهها کمتر قابلاعتماد هستند، زیرا اغلب از منابع مختلف استخراج میشوند و در حالت خام باقی میمانند؛ بدون اینکه ابتدا از نظر دقت و سازگاری بررسی شوند.
- چابکی و مقیاسپذیری: دریاچههای داده پلتفرمهای بسیار چابکی هستند. ازآنجاکه ساختار داده ها در آنها تغییر نمیکند، میتوانند در صورت نیاز، پیکربندی و گسترش داده شوند تا نیازهای دادهای در حال تغییر و نیازهای تجاری را برآورده کنند. انبارهای داده به دلیل طرحواره سفتوسخت و مجموعه داده های آماده، انعطافپذیری کمتری دارند.
- امنیت: انبارهای داده دارای حفاظتهای امنیتی قدرتمندتری هستند، زیرا مدت بیشتری از ظهور آنها گذشته و با فناوری تکامل پیدا کردهاند. اما روشهای امنیتی دریاچه دادهها در حال بهبود هستند و چارچوبها و ابزارهای امنیتی مختلفی نیز برای محیطهای کلان داده در دسترس قرار میدهند.
به سبب وجود این تفاوتها، امروزه بسیاری از سازمانها هم از انبار داده و هم از دریاچه داده استفاده میکنند؛ اغلب به شکل ترکیبی. درواقع سازمانهای دارای انبار داده، با دیدن مزایای دریاچههای داده، انبار خود را بهگونهای توسعه میدهند که شامل دریاچههای داده باشد تا بتوانند از قابلیتهای جستجوی متنوع، موارد استفاده از علم داده و قابلیتهای پیشرفته، برای کشف مدلهای اطلاعاتی جدید استفاده کنند. گارتنر این تکامل را «راهحل مدیریت داده برای تجزیهوتحلیل» یا “DMSA” نامگذاری میکند.
مزایای دریاچه داده
دریاچه داده، پایهای برای علم داده و برنامههای کاربردی تجزیهوتحلیل پیشرفته فراهم کرده و بهاینترتیب، به سازمانها کمک میکند تا به طور مؤثرتری عملیات کسبوکار خود را مدیریت و روندها و فرصتهای تجاری را شناسایی کنند. برای مثال، یک سازمان میتواند از مدلهای پیشبینی رفتار خرید مشتری، برای بهبود کمپینهای تبلیغاتی و بازاریابی آنلاین خود استفاده کند. تجزیهوتحلیل در دریاچه داده همچنین میتواند به مدیریت ریسک، کشف تقلب، تعمیر و نگهداری تجهیزات و سایر عملکردهای تجاری نیز کمک کند.
مانند انبارهای داده، دریاچههای داده نیز با ترکیب مجموعه دادههای موجود در سیستمهای مختلف در یک مخزن متمرکز، به تجزیه سیلوهای داده کمک میکنند؛ بنابراین data lakeها به تیمهای علم داده، دید کاملی از دیتای موجود میدهند و فرایند یافتن داده های موردنیاز و آمادهسازی آنها برای استفادههای تحلیلی را ساده میکنند. همچنین میتواند با حذف پلتفرمهای داده تکراری در یک سازمان، به کاهش هزینههای فناوری اطلاعات و مدیریت داده ها کمک کند.

دریاچههای داده با ترکیب مجموعه دادههای موجود در سیستمهای مختلف در یک مخزن متمرکز، به تجزیه سیلوهای داده کمک میکنند
از دیگر مزایای دریاچه داده میتوان به موارد زیر اشاره کرد:
- دانشمندان داده و سایر کاربران را قادر میسازد تا مدلهای داده، برنامههای کاربردی تحلیل دیتا و پرسوجوها را در لحظه ایجاد کنند،
- پیادهسازی دریاچه داده نسبتاً ارزان است؛ زیرا Hadoop، Spark و بسیاری از فناوریهای دیگر که برای ساخت آنها استفاده میشوند متنباز هستند و با کمترین هزینه میتوانند روی سختافزار نصب شوند،
- طراحی طرحواره و فعالیتهای مربوط به فشرده و پاکسازی، تبدیل و آمادهسازی دادهها را میتوان تا زمانی که نیاز کسبوکاری واضح به دادهها مشخص شود، به تعویق انداخت،
- روشهای تحلیلی مختلفی را میتوان در محیطهای دریاچه داده استفاده کرد؛ از جمله مدلسازی پیشبینیکننده، یادگیری ماشین، تجزیهوتحلیل آماری، متنکاوی، تجزیهوتحلیل بلادرنگ و پرسوجوی SQL.
درواقع میتوان گفت دریاچه داده با ایجاد توانایی استفاده از دادهها و منابع بیشتر، در زمان کمتر و توانمندسازی کاربران برای همکاری و تحلیل دادهها به روشهای مختلف، منجر به تصمیمگیری بهتر و سریعتر در کسبوکارها میشود. نمونههایی که data lake میتواند برای یک سازمان داده ارزشافزوده ایجاد کند، عبارتاند از:
- بهبود تعاملات با مشتری: دریاچه داده میتواند دادههای مشتری از یک پلتفرم CRM را با تحلیل رسانههای اجتماعی و سیستمهای سازمانی ترکیب کند تا در شناسایی سودآورترین گروه مشتریان، علت ریزش آنها و ارائه تبلیغات یا پاداشها، به یک سازمان کمک کند. این موضوع در نهایت باعث افزایش وفاداری مشتریان خواهد شد.
- بهبود فرایندهای نوآوری، تحقیق و توسعه: یک Data Lake میتواند به تیمهای تحقیق و توسعه کمک کند تا فرضیههای خود را آزمایش کنند، مفروضات را اصلاح و نتایج بهدستآمده را ارزیابی کنند؛ مانند انتخاب مواد مناسب در طراحی محصول که منجر به عملکرد سریعتر میشود، انجام تحقیقات ژنومی که منجر به ساخت داروی مؤثرتر میشود، یا درک تمایل مشتریان به شیوههای مختلف پرداخت.
- افزایش کارایی عملیاتی: امروزهاینترنت اشیا (IoT)، راههای بیشتری را برای جمعآوری دادهها در فرایندهایی مانند تولید، از دادههای در لحظه دستگاههای متصل به اینترنت، فراهم میکند. یک دریاچه داده، ذخیره و اجرای تجزیهوتحلیل روی داده های تولید شده توسط ماشینآلات را برای کشف راههایی جهت کاهش هزینههای عملیاتی و افزایش کیفیت، آسان میکند.
معایب دریاچه داده
علیرغم مزایای تجاری که دریاچههای داده ارائه میکنند، استقرار و مدیریت آنها میتواند یک فرایند دشوار باشد. چالش اصلی در مقابل معماری دریاچه داده این است که در آن، داده های خام بدون نظارت بر محتویات آنها، ذخیره میشوند. درواقع برای اینکه یک دریاچه داده بتواند داده ها را قابلاستفاده کند، باید مکانیسمهای تعریف شدهای برای فهرستنویسی و ایمنسازی دیتا داشته باشد. بدون این عناصر، دادههای موردنیاز را نمیتوان پیدا یا به آنها اعتماد کرد که منجر به ایجاد «باتلاق دادهها» میشود. برای برآوردن نیازهای مخاطبان مختلف، دریاچههای داده نیاز به تعیین حاکمیت، سازگاری معنایی و کنترلهای دسترسی دارند.
برخی از مهمترین چالشهایی که دریاچههای داده برای سازمانها ایجاد میکنند، عبارتاند از:
- ایجاد باتلاقهای داده (Data Swamps): یکی از بزرگترین چالشهای کسبوکارها، جلوگیری از تبدیل دریاچه داده به باتلاق داده است. درواقع اگر data lake بهدرستی راهاندازی و مدیریت نشود، میتواند به محلی برای جمعآوری بیهوده داده ها تبدیل شود. بهاینترتیب، کاربران ممکن است آنچه نیاز دارند را پیدا نکنند، مدیران داده در ردیابی دادههای ذخیره شده به مشکل میخورند و با سرازیرشدن داده مواجه میشوند.
- تکنولوژی سربار: طیف گسترده فناوریهایی که میتوان در پیادهسازی دریاچه داده مورد استفاده قرار داد، استقرار data lake را پیچیده میکند. بنابراین سازمانها باید در ابتدا ترکیب مناسبی از فناوریهای موردنیاز برای رفع نیازهای مدیریت داده و تحلیل دیتای خاص خود را شناسایی و سپس نسبت به نصب آنها اقدام کنند؛ اگرچه امروزه راهکارهای مبتنی بر ابر، این مرحله را آسانتر کرده است.
- هزینههای غیرمنتظره: اگرچه ممکن است هزینههای اولیه راه اندازه دریاچه داده زیاد نباشد، اما اگر سازمانها بهدرستی فضای دریاچه داده را مدیریت نکنند، ممکن است با هزینههای زیادی مواجه شوند. برای مثال، در صورت استفاده بیش از حد، کسبوکارها ممکن است صورتحسابهای غافلگیرکنندهای برای دریاچههای داده مبتنی بر ابر دریافت کنند. همچنین نیاز به بزرگتر کردن دریاچههای داده برای حجمهای کاری بالا نیز هزینهها را افزایش میدهد.
- حاکمیت داده: یکی از اهداف دریاچه داده این است که داده های خام را همانطور که هستند، برای استفادههای مختلف تحلیلی ذخیره کند. اما بدون مدیریت مؤثر دریاچههای داده، سازمانها ممکن است با مسائل مربوط به کیفیت، ثبات و قابلیت اطمینان داده ها آسیب ببینند. این مشکلات میتوانند برنامههای تحلیلی را مختل و نتایج ناقصی ایجاد کنند که منجر به تصمیمهای تجاری نامناسب میشود.
دریاچه داده مبتنی بر ابر
در ابتدا، بیشتر دریاچههای داده در مراکز داده داخلی هر سازمان مستقر میشدند. اما امروز بخشی از معماری داده های ابری در بسیاری از کسبوکارها هستند. دریاچههای داده یک گزینه ایدهآل برای استقرار در فضای ابری هستند، زیرا فضای ابری عملکرد، مقیاسپذیری، قابلیت اطمینان، دردسترسبودن و مجموعه متنوعی از موتورهای تحلیلی و صرفهجویی در مقیاس عظیمی را ارائه میدهد.
تحقیقات ESG نشان داد که 39٪ از کسبوکارها، فضای ابری را به عنوان بستر اصلی استقرار دریاچه داده برای تجزیهوتحلیل داده و 41٪ آنها، از این فضا برای پیادهسازی انبارهای داده بهره میگیرند. مهمترین دلایلی که مشتریان ابر، این فضا را به عنوان یک مزیت برای استقرار دریاچههای داده میشناسند؛ امنیت بهتر، زمان سریعتر برای استقرار، دسترسی بهتر، بهروزرسانیهای مکرر ویژگیها، ظرفیت بیشتر، گستردگی جغرافیایی بیشتر و کاهش هزینههای مرتبط با استفاده است.
نرم افزار BI همکاران سیستم، همراه کسبوکارها در تحلیل دادهها
دریاچه های داده یک رویکرد قدرتمند و همهکاره برای مدیریت کلان داده ها ارائه میدهند. توانایی آنها برای ذخیره مقادیر زیادی داده در قالب اصلی و مقیاسپذیری ذاتی آنها، سازمانها را قادر میسازد تا به طیف وسیعتری از اطلاعات دسترسی داشته باشند و پتانسیل خود را برای رسیدن به بینشهای عمیقتر، باز کنند.
نرم افزار BI همکاران سیستم، به کسبوکارها در جمعآوری، تحلیل، تبدیل و تفسیر دادهها و تبدیل آن به اطلاعات قابل درک و اعتماد، کمک میکند. در این راهکار داشبوردهای تحلیلی متنوعی به شکل پیشفرض آماده شده است که با کمک آنها میتوان دید جامعی نسبت به فرایندهای سازمان کسب کرد و در نهایت، تصمیمگیری استراتژیک و هوشمندانهتری داشت. برای کسب اطلاعات بیشتر، با ما در تماس باشید.
منابع
- oracle.com
- aws.amazon.com
- techtarget.com
- cloud.google.com