
حجم فزاینده منابع داده و به دنبال آن، داده ها باعث شده است تا امروزه علم داده یکی از سریعترین علوم درحالرشد هر صنعت باشد. در دنیای دیجیتال، سازمانها برای تفسیر داده ها و ارائه توصیههای عملی برای بهبود نتایج کسبوکار، به طور فزایندهای به دانشمندان داده متکی هستند. در نتیجه، جای تعجب نیست که نقش دانشمند داده توسط هاروارد بیزینس ریویو بهعنوان «جذابترین شغل قرن بیست و یکم» شناخته شده باشد!
در این مقاله به معرفی علم داده پرداخته و مزایای آن برای کسبوکارها را مورد بررسی قرار میدهیم. در ادامه به معرفی تکنیکهای علم داده و مهمترین ابزارهای آن پرداخته و نقش دانشمند داده در سازمان را تحلیل میکنیم. بررسی تفاوت علم داده با هوش تجاری و نقش رایانش ابری در توسعه علم داده، بخشهای دیگری از این مقاله است که شما را به خواندن آن دعوت میکنیم.
علم داده چیست؟
علم داده (Data Science) را میتوان مطالعه داده ها، برای رسیدن به یک بینش معنادار در راستای کسبوکار دانست. دیتا ساینس یک رویکرد چندرشتهای است که اصول و شیوههای ریاضی، آمار، هوش مصنوعی و مهندسی کامپیوتر را برای تجزیهوتحلیل حجم زیادی از دادهها ترکیب میکند. این تجزیهوتحلیل به دانشمندان داده کمک میکند تا سؤالاتی مانند آنچه اتفاق افتاده، چرا اتفاق افتاده، چه اتفاقی خواهد افتاد و با نتایج ایجاد شده چه کاری میتوان انجام داد، را بپرسند و به آنها پاسخ دهند. درنهایت ازبینشهای ایجاد شده میتوان برای هدایت تصمیمگیری و برنامهریزی استراتژیک کسبوکار استفاده کرد.
چرخه حیات علم داده شامل نقشها، ابزارها و فرایندهای مختلفی است که تحلیلگران را قادر میسازد تا از داده ها، بینشهای عملی به دست آورند. به طور معمول، یک پروژه علم داده مراحل زیر را طی میکند:
- جمعآوری داده ها: چرخه حیات علم داده با جمعآوری داده ها آغاز میشود؛ شامل داده های ساختاریافته خام و داده های بدون ساختار، از منابع مرتبط و با روشهای مختلف. روشهای جمعآوری داده میتوانند شامل ورود دستی، جستجوی وب و جریان دادههای در لحظه از سیستمها و دستگاهها باشند. منابع داده نیز میتواند شامل دادههای ساختاریافته، مانند دادههای مشتری و دادههای بدون ساختار مانند فایلهای گزارش، ویدئو، صدا، تصاویر، اینترنت اشیا (IoT)، رسانههای اجتماعی و غیره باشد.
- ذخیرهسازی و پردازش داده ها: ازآنجاکه داده ها میتوانند فرمتها و ساختارهای متفاوتی داشته باشند، سازمانها باید سیستمهای ذخیرهسازی متفاوتی را بر اساس نوع دادههایی که باید جمعآوری شوند، در نظر بگیرند. تیمهای مدیریت داده به تنظیم استانداردهایی در مورد ذخیرهسازی و ساختار دادهها کمک میکنند که گردش کار تحلیلها، یادگیری ماشین و مدلهای یادگیری عمیق را تسهیل میکند. این مرحله شامل پاکسازی داده ها، کپیبرداری، تبدیل و ترکیب داده ها با استفاده از فرایند ETL (استخراج، تبدیل، بارگذاری) یا سایر فناوریهای یکپارچهسازی داده ها است. آمادهسازی داده برای افزایش کیفیت داده ها قبل از قرارگرفتن در انبار داده، دریاچه داده یا مخازن داده دیگر ضروری است.
- تجزیهوتحلیل داده ها: در این مرحله، دانشمندان داده برای بررسی سوگیریها، الگوها، محدودهها و توزیع مقادیر در داده ها، شروع به تجزیهوتحلیل داده میکنند. همچنین به تحلیلگران اجازه میدهد تا از ارتباط میان دادهها، برای مدلسازیهای مختلف تجزیهوتحلیل پیشبینیکننده، یادگیری ماشین یا یادگیری عمیق، استفاده کنند. درنهایت، بسته بهدقت مدل، سازمانها میتوانند برای تصمیمگیری تجاری به این بینشها متکی باشند و از امکان مقیاسپذیری بیشتری برخوردار شوند.
- تعامل: در نهایت، بینشها در قالب گزارشها و سایر روشهای تجسم داده ارائه میشوند که درک و تأثیر آنها بر تجارت را برای تحلیلگران کسبوکار و سایر ذینفعان آسانتر میکند. یک زبان برنامهنویسی علم داده مانند R یا Python شامل اجزایی برای مصور ساختن داده است و دانشمندان داده میتوانند آنها را به طور اختصاصی نیز مورداستفاده قرار دهند.
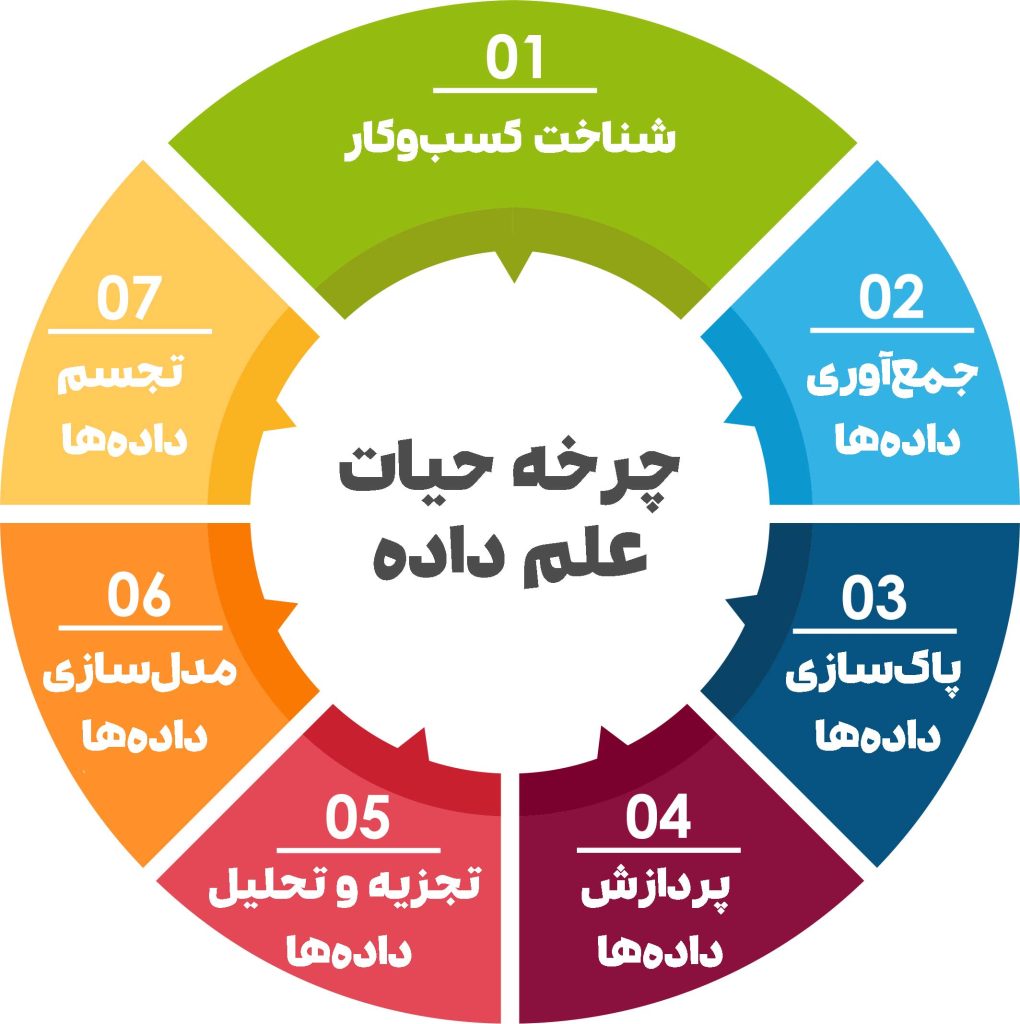
چرخه حیات علم داده
مزایای علم داده برای کسبوکارها در چیست؟
علم داده مهم است زیرا ابزارها، روشها و فناوریها را برای استخراج معنا از دادهها، ترکیب میکند. سازمانهای مدرن امروز، غرق در داده ها هستند و استفاده از دستگاههایی که میتوانند به طور خودکار اطلاعات را جمعآوری و ذخیره کنند، روبهافزایش است. سیستمهای آنلاین و درگاههای پرداخت، دادههای زیادی را در زمینههای تجارت الکترونیک، پزشکی، مالی و هر جنبه دیگری از زندگی انسان جمعآوری میکنند و بهاینترتیب، داده های متنی، صوتی و تصویری، در مقادیر زیاد، در دسترس قرار دارد.
دیتا ساینس در حال متحول کردن شیوه عملکرد سازمانها است. بسیاری از کسبوکارها، صرفنظر از اندازه، به یک استراتژی قوی علم داده برای پیشبرد رشد و حفظ مزیت رقابتی نیاز دارند. برخی از مزایای کلیدی علم داده برای کسبوکارها عبارت است از:
- شناسایی الگوهای ناشناخته و تحولآفرین: علم داده به کسبوکارها اجازه میدهد تا الگوها و روابط جدیدی را کشف کنند که پتانسیل تغییر سازمان را دارند. درواقع این علم میتواند تغییرات کمهزینه در مدیریت منابع را برای رسیدن به حداکثر تأثیر بر حاشیه سود، نشان دهد. برای مثال، یک شرکت تجارت الکترونیکی از دیتا ساینس استفاده میکند تا نتیجه پاسخگویی به درخواستهای مشتریان پس از پایان ساعات کاری را شناسایی کند. تحلیل داده ها به این سازمان نشان میدهد که مشتریان در صورت دریافت پاسخ سریع بهجای پاسخ در روز کاری بعدی، احتمال خرید بیشتری دارند و با اجرای خدمات مشتری 24 ساعته، کسبوکار میتواند درآمد خود را 30 درصد افزایش دهد.
- ایجاد نوآوری در تولید محصولات و راهحلهای جدید: علم داده میتواند شکافها و مشکلاتی را آشکار کند که در حالت عادی موردتوجه قرار نمیگیرند. درواقع ایجاد بینش در مورد تصمیمات خرید، بازخورد مشتری و فرایندهای تجاری میتواند باعث بروز نوآوری در عملیات داخلی و راهحلهای خارجی یک کسبوکار شود. برای مثال، یک سازمان میتواند از علم داده برای جمعآوری و تجزیهوتحلیل نظرات مشتریان در مورد پرداخت آنلاین استفاده کند. تجزیه و تحلیلها نشان میدهد که مشتریان در دورههای اوج خرید، رمزهای عبور خود را فراموش میکنند و از سیستم فعلی بازیابی رمز عبور ناراضی هستند. بهاینترتیب، این شرکت میتواند راهحل بهتری را برای ارائه رمز عبور ابداع کند و شاهد افزایش قابلتوجهی در رضایت مشتریان خود باشد.
- بهینهسازی در لحظه: برای کسبوکارها، بهویژه شرکتهای بزرگ، بسیار چالشبرانگیز است که به شرایط در حال تغییر، در لحظه پاسخ دهند. این موضوع میتواند باعث بروز زیانهای قابلتوجه یا اختلال در فعالیتهای تجاری شود. دیتا ساینس میتواند به کسبوکارها کمک کند تا تغییرات را پیشبینی کرده و به شرایط مختلف، واکنش بهینه نشان دهند. برای مثال، یک شرکت حملونقل مبتنی بر کامیون از علم داده برای کاهش زمان خرابی کامیونها استفاده میکند. آنها مسیرها و تغییر الگوهایی را که منجر به خرابی سریعتر ماشینها میشوند را شناسایی میکنند و برنامههای کامیونها را تغییر میدهند. آنها همچنین میتوانند فهرستی از قطعات یدکی معمولی که نیاز به تعویض مکرر دارند را تنظیم کنند تا کامیونها سریعتر تعمیر شوند.
مهمترین تکنیک های علم داده
متخصصان علم داده از سیستمهای محاسباتی برای انجام فرایند دیتا ساینس استفاده میکنند. اگرچه جزئیات تکنیکهای علم داده با یکدیگر متفاوت هستند، اما در پشت تمامی آنها، چند اصل اساسی نهفته است:
- به یک ماشین آموزش دهید که چگونه داده ها را بر اساس یک مجموعه داده شناخته شده، مرتب کند. بهعنوانمثال، کلمات کلیدی نمونه با مقدار مرتبسازی به کامپیوتر داده میشود: «شاد» مثبت است، درحالیکه «نفرت» منفی است.
- داده های ناشناخته را به دستگاه بدهید و به آن اجازه دهید مجموعه داده ها را به طور مستقل مرتب کند.
- عدم دقت نتایج را در نظر بگیرید و ضریب احتمال نتیجه را مدیریت کنید.
تکنیکهای برتر دیتا ساینس مورداستفاده توسط دانشمندان داده عبارتند از:
طبقه بندی (Classification)
طبقه بندی داده ها به معنای مرتبسازی داده ها در گروهها یا دستههای خاص است. درواقع کامپیوترها برای شناسایی و مرتبسازی داده ها آموزشدیدهاند. از مجموعه داده های شناخته شده، برای ساختن الگوریتمهای تصمیمگیری استفاده میشود که بهسرعت داده ها را پردازش و دستهبندی میکنند.
مثالهای زیر طبقهبندی داده ها را در یک کسبوکار نشان میدهد:
- دستهبندی محصولات بهعنوان محبوب یا غیرمحبوب
- مرتبکردن برنامههای بیمه در دستهبندیهای پرخطر یا کمخطر
- دستهبندی نظرات کاربران رسانههای اجتماعی در دستههای مثبت، منفی یا خنثی
رگرسیون (Regression)
رگرسیون روشی برای یافتن رابطه میان دو داده بهظاهر نامرتبط است. این اتصال معمولاً پیرامون یک فرمول ریاضی مدلسازی شده و به شکل نمودار یا منحنی نشان داده میشود. هنگامی که مقدار یک داده مشخص است، از رگرسیون برای پیشبینی داده دیگر استفاده میشود.
از مثالهای رگرسیون در علم داده میتوان به موارد زیر اشاره کرد:
- شناسایی میزان شیوع بیماریهای منتقل شده از طریق هوا
- شناسایی رابطه میان رضایت مشتری و تعداد کارکنان
- شناسایی رابطه میان تعداد ایستگاههای آتشنشانی و تعداد جراحات ناشی از آتشسوزی در یک مکان خاص
خوشه بندی (Clustering)
خوشه بندی روشی برای گروهبندی داده های نزدیک به هم، برای جستجوی الگوها و ناهنجاریها است. خوشهبندی با مرتبسازی متفاوت است زیرا داده ها را نمیتوان به طور دقیق در دستههای ثابت طبقهبندی کرد؛ ازاینرو در خوشهبندی، داده ها در محتملترین روابط گروهبندی میشوند. با استفاده از خوشهبندی داده ها، میتوان الگوها و روابط جدید را کشف کرد.
مثالهای خوشهبندی داده عبارتند از:
- گروهبندی مشتریان با رفتار خرید مشابه برای بهبود خدمات مشتری
- گروهبندی ترافیک شبکه برای شناسایی الگوهای استفاده روزانه و شناسایی سریعتر حمله شبکه
- گروهبندی مقالات در چند دسته خبری مختلف برای یافتن محتوای اخبار جعلی
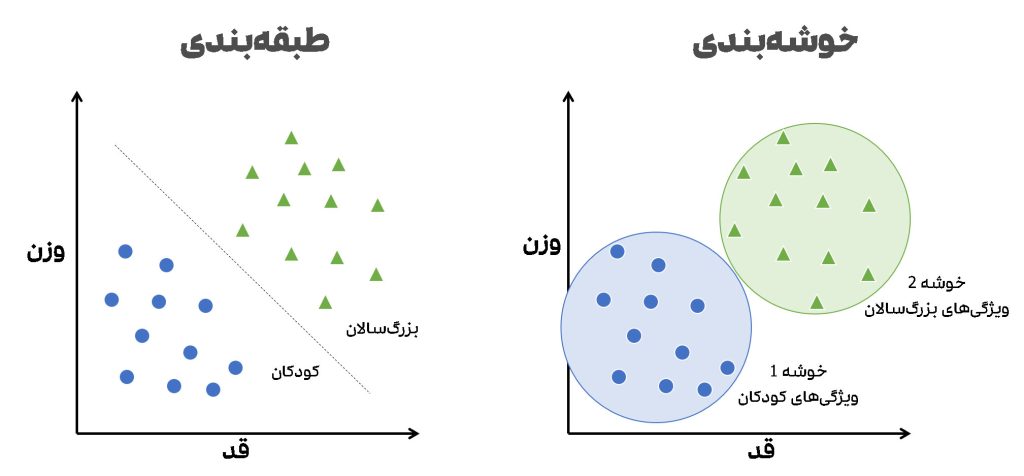
تفاوت طبقه بندی و خوشه بندی
علم داده با دانشمند داده چه تفاوتی دارد؟
دیتا ساینس بهعنوان یک رشته در نظر گرفته میشود، درحالیکه دانشمند داده (Data scientist) متخصص این حوزه است. دانشمندان داده لزوماً مسئول مستقیم تمام فرایندهای درگیر در چرخه حیات علم داده نیستند. برای مثال، منابع ورودی داده معمولاً توسط مهندسان داده مدیریت میشود اما دانشمند داده ممکن است توصیههایی در مورد نوع داده های مفید یا موردنیاز ارائه دهد. اگرچه دانشمندان داده میتوانند مدلهای یادگیری ماشین بسازند، اما در سطوح بالاتر، برای بهینهسازی یک برنامه و اجرای سریعتر آن، به مهارتهای مهندسی نرمافزار نیاز دارند. در نتیجه، برای یک دانشمند داده لازم است که برای توسعه مدلهای یادگیری ماشین، با مهندسان نرمافزار تعامل داشته باشد.
مسئولیتهای دانشمند داده میتواند با یک تحلیلگر داده همپوشانی داشته باشد؛ بهویژه در زمینه تجزیهوتحلیل دادههای اکتشافی و تجسم دادهها. بااینحال، مجموعه مهارتهای یک دانشمند داده معمولاً بیشتر از مهارتهای یک تحلیلگر داده است. برای مثال دانشمندان داده از زبانهای برنامهنویسی رایج مانند R و Python برای استنتاج آماری و تجسم داده ها استفاده میکنند. برای انجام این وظایف، دانشمندان داده به علوم کامپیوتر و مهارتهای علمی خالص، فراتر از یک تحلیلگر کسبوکار معمولی یا تحلیلگر داده، نیاز دارند. دانشمند داده همچنین باید از ویژگیهای کسبوکار مانند فرایند تولید، تجارت الکترونیک یا مراقبتهای بهداشتی نیز درکی داشته باشد.
مسیر یادگیری علم داده
یک دانشمند داده میتواند از طیف وسیعی از تکنیکها، ابزارها و فناوریهای مختلف بهعنوان بخشی از فرایند مهندسی داده استفاده کند. معمولاً سه مرحله برای تبدیلشدن به یک دانشمند داده وجود دارد:
- کسب مدرک کارشناسی در یکی از رشتههای IT، علوم کامپیوتر، ریاضی، فیزیک یا سایر رشتههای مرتبط
- دریافت مدرک کارشناسی ارشد در علم داده یا رشتههای مرتبط
- کسب تجربه در زمینه موردعلاقه
به طور خلاصه، یک دانشمند داده باید:
- اطلاعات کافی در مورد کسبوکار داشته باشد تا بتواند سؤالات درست را بپرسد و مشکلات کسبوکار را شناسایی کند،
- در کنار نرم افزار BI از آمار و علوم کامپیوتر نیز در تجزیهوتحلیل داده ها استفاده کند،
- برای تهیه و استخراج داده ها، از طیف گستردهای از ابزارها و تکنیکهای روز استفاده کند؛ از پایگاه داده و SQL تا دادهکاوی و روشهای یکپارچهسازی داده ها،
- با استفاده از تجزیهوتحلیل پیشبینی و هوش مصنوعی (AI)، از جمله مدلهای یادگیری ماشین، پردازش زبان طبیعی و یادگیری عمیق، به استخراج بینش از کلان داده ها بپردازد،
- برنامههایی بنویسد که پردازش و محاسبات داده ها را خودکار میکند،
- با تجسم و توضیح هرچه بهتر داده ها، بتواند بهوضوح معنای نتایج بهدستآمده را به تصمیمگیرندگان و ذینفعان در هر سطحی منتقل کند،
- بتواند شیوه استفاده از نتایج برای حل مشکلات کسبوکار را توضیح دهد،
- با سایر اعضای تیم علم داده مانند تحلیلگران داده و کسبوکار، معماران داده، مهندسان داده و توسعهدهندگان برنامه همکاری کند.
در دنیای امروز، این مهارتها با تقاضای زیادی مواجه هستند و در نتیجه، بسیاری از افرادی که وارد حرفه علم داده میشوند، باید انواع موضوعات مهندسی داده مانند گواهینامهها و دورههای علوم داده را پشت سر بگذارند.
ابزارهای علم داده
دانشمندان داده برای انجام تجزیهوتحلیل داده های اکتشافی و رگرسیون آماری، به زبانهای برنامهنویسی متکی هستند که از مدلسازی آماری ازپیشساخته شده، یادگیری ماشین و قابلیتهای گرافیکی پشتیبانی میکنند. این زبانها شامل موارد زیر هستند:
- R Studio: یک زبان برنامهنویسی متنباز و محیطی برای توسعه محاسبات آماری و گرافیک
- پایتون: یک زبان برنامهنویسی پویا و انعطافپذیر که شامل کتابخانههای متعددی مانند NumPy، Pandas، Matplotlib برای تجزیهوتحلیل سریع داده ها است.
همچنین برای تسهیل اشتراکگذاری کد و سایر اطلاعات، دانشمندان داده ممکن است از نوتبوکهای GitHub و Jupyter استفاده کنند.

دانشمندان داده برای تحلیل دیتا به ابزارهای مختلف آماری، هوش مصنوعی و گرافیکی نیاز دارند
دانشمندان داده برای استفاده از پلتفرمهای پردازش داده های بزرگ مانند Apache Spark، باید در چارچوب متنباز Apache Hadoop و پایگاه های داده NoSQL نیز مهارت کسب کنند. آنها همچنین با طیف گستردهای از ابزارهای تجسم داده ها، از جمله ابزارهای گرافیکی ساده و صفحه گسترده (مانند مایکروسافت اکسل)، ابزارهای تجسم تجاری ساخته شده برای هدف مانند Tableau و IBM Cognos، و ابزارهای متنباز مانند D3.js (یک کتابخانه جاوا اسکریپت برای ایجاد تجسم داده های تعاملی) و نمودارهای RAW مهارت دارند. این دانشمندان برای ساخت مدلهای یادگیری ماشین، اغلب به چارچوبهای مختلف مانند PyTorch، TensorFlow، MXNet و Spark MLib نیز روی میآورند.
باتوجهبه شیبدار بودن منحنی یادگیری علم داده، بسیاری از شرکتها به دنبال افزایش سرعت در بازگشت سرمایه خود از طریق پروژههای هوش مصنوعی هستند. در همین راستا، کسبوکارها اغلب برای استخدام استعدادهای موردنیاز برای تحقق پتانسیل کامل پروژه دیتا ساینس تلاش میکنند. برای رفع این شکاف، آنها به پلتفرمهای علم دادههای چند شخصی (multipersona data science) و یادگیری ماشین (DSML) روی میآورند و نقش «شهروند دانشمند داده» را پررنگ میکنند.
پلتفرمهای چند شخصی DSML از اتوماسیون، پرتالهای سلفسرویس و رابطهای کاربری کمکد/بدون کد استفاده میکنند تا افرادی که پیشزمینه کمی در فناوریهای دیجیتال یا علم داده دارند، بتوانند با استفاده از دیتا ساینس و یادگیری ماشین، به ایجاد ارزش تجاری بپردازند. این پلتفرمها همچنین با ارائه یک رابط فنی، از دانشمندان داده خبره نیز پشتیبانی میکنند. استفاده از پلتفرم DSML چند شخصی، همکاری در سراسر سازمان را تشویق میکند.
علم داده و رایانش ابری
رایانش ابری با ایجاد دسترسی به قدرت پردازش اضافی، ذخیرهسازی و سایر ابزارهای موردنیاز برای پروژههای علم داده، دیتا ساینس را گستردهتر میکند.
ازآنجاکه علم داده اغلب روی بیگ دیتا کار میکند، وجود ابزارهایی که بتوانند با اندازه داده ها مقیاس شوند، بهویژه برای پروژههای حساس به زمان، بسیار مهم هستند. راهحلهای ذخیرهسازی ابری، مانند دریاچههای داده، دسترسی به زیرساختهای ذخیرهسازی بزرگی را فراهم میکنند که میتوانند حجم زیادی از دادهها را بهراحتی دریافت و پردازش کنند. این سیستمهای ذخیرهسازی، برای کاربران نهایی انعطافپذیری را فراهم میکند و به آنها اجازه میدهد تا خوشههای بزرگ داده را مدیریت کنند. پلتفرمهای ابری معمولاً مدلهای قیمتگذاری متفاوتی دارند، مانند هر بار استفاده یا اشتراک، تا نیازهای کاربر نهایی خود را برآورده کنند؛ چه یک شرکت بزرگ یا یک استارتآپ کوچک.
همچنین باتوجهبه کاربرد گسترده فناوریهای متنباز در علم داده، میزبانی در فضای ابری دانشمندان داده را از نصب، پیکربندی، نگهداری یا بهروزرسانی آنها به شکل محلی بینیاز میکند. ارائهدهندگان خدمات ابری، دانشمندان داده را قادر میسازد تا برخی از مدلهای موردنیاز خود را بدون کدنویسی بسازند و دسترسی بیشتری را به نوآوریهای و بینش داده فراهم کنند.
علم داده با هوش تجاری چه تفاوتی دارد؟
علم داده و هوش تجاری (BI) دو اصطلاحی هستند که معمولاً با یکدیگر اشتباه گرفته میشوند، زیرا هر دو به داده های سازمان و تجزیهوتحلیل این داده ها مربوط میشوند. اما باید گفت که این دو واژه، در میزان تمرکز بر داده، با یکدیگر متفاوت هستند.
هوش تجاری (BI) یک اصطلاح گسترده برای فناوریهایی است که آمادهسازی داده ها، دادهکاوی، مدیریت داده ها و تجسم داده ها را امکانپذیر میکند. ابزارها و فرایندهای هوش تجاری به کاربران نهایی این امکان را میدهند که اطلاعات عملیاتی را از دادههای خام شناسایی کنند و تصمیمگیری مبتنی بر داده را در سازمانها در صنایع مختلف تسهیل کنند. درحالیکه ابزارهای علم داده در بسیاری از این موارد با یکدیگر همپوشانی دارند، هوش تجاری بیشتر بر دادههای گذشته تمرکز میکند و بینشهای نرم افزار BI ماهیت توصیفیتری دارند. BI به سمت داده های ایستا (تغییرناپذیر) که معمولاً ساختاریافته هستند، حرکت میکند. درحالیکه مهندسی داده از داده های توصیفی استفاده کرده و آنها را برای تعیین متغیرهای پیشبینیکننده به کار میگیرد که درنهایت برای دستهبندی داده ها یا پیشبینیها استفاده میشود.
در نهایت میتوان گفت علم داده و BI منحصربهفرد نیستند و سازمانهای هوشمند، برای درک کامل و استخراج ارزش از دادههای خود، از هر دو آنها استفاده میکنند. راهکار هوشمندی تجاری همکاران سیستم یکی از ابزارهای BI برای کسبوکارها است که با جمعآوری، تحلیل، تبدیل و تفسیر دادهها و تبدیل آن به اطلاعات قابلدرک و اعتماد، به سازمانها کمک میکند تا با تصمیمگیریهای استراتژیک و هوشمندانه، حضور مؤثرتری در بازار داشته باشند.
منابع:
- ibm.com
- aws.amazon.com